




Captioning has become central to media consumption in the United States − whether via traditional broadcast, social media channels, or through streaming media − and it continues to grow across all platforms. From the conference room to the classroom to the living room, captioning makes information attainable and retainable for tens of millions people of all abilities across all walks of life.
In recognition of Court Reporting and Captioning Week, we wanted to take a look at the differences between captions created by skilled, professional captioners, like those at VITAC and other captioning companies, and those created solely by auto speech recognition (ASR) programs. And, really, you don’t have to look too far to find them.
Captions traditionally are created by people − highly trained professionals who understand the nuances of language and bring human sensitivities and contextual awareness to the captioning table. VITAC, a full-service captioning company and industry leader in captioning and accessible media solutions for more than three decades, strongly believes in the essential human element in creating captions. Our captioners are dedicated company employees − recruited, trained, tested, and reviewed by VITAC to ensure round-the-clock, reliable, secure, and accurate customer service.
But as technology continues to play a greater role in all facets of life, the captioning sector is no exception. As ASR programs are becoming more prevalent, some are promoting them as an alternative captioning option.
The appeal of ASR is that the software provides instant, realtime captions and, perhaps most importantly, it’s inexpensive or free, as in the case of YouTube. It’s a relatively simple procedure that ticks the right boxes, except for the most important one – providing accurate, reliable, error-free onscreen information.
Though speech automation certainly has a role in creating captions, the programs need a human hand (and eye and ear and voice and intelligence) guiding and assisting it. The problem in quality lies with “unassisted” captions, where a human is not involved.
Even the most advanced speech recognition programs lack human intelligence and are, in essence, a guess by machines at the spoken word. Without having a human eye or ear monitoring the machine for such things as accuracy and completeness, ASR routinely fails to meet expectations.
In fact, there is a petition before the Federal Communications Commission (FCC), filed by TDI and nearly a dozen other organizations, that asks the FCC to develop objective, technology-neutral metrics for ASR software and caption quality. The petition seeks an FCC ruling on the use of ASR technologies, and to explain how its “best practices” for video programmers, caption vendors, and captioners apply to ASR.
VITAC complies with the Federal Communications Commission’s Caption Quality Best Practices for accuracy, synchronicity, completeness, and placement.
Accuracy
VITAC helped write the requirements on caption accuracy, which state, among other things, that proper names be spelled correctly, punctuation be correct, speakers be identified, subject changes noted, song lyrics be captioned, and onscreen caption placement avoid any other graphics.
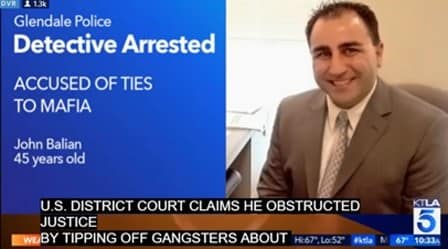
Among the areas where unassisted ASR comes up short include not being able to caption accented speakers or rapid-fire conversations, or displaying captions (such as below) that simply do not match the words spoken and appear as nonsensical gibberish onscreen.

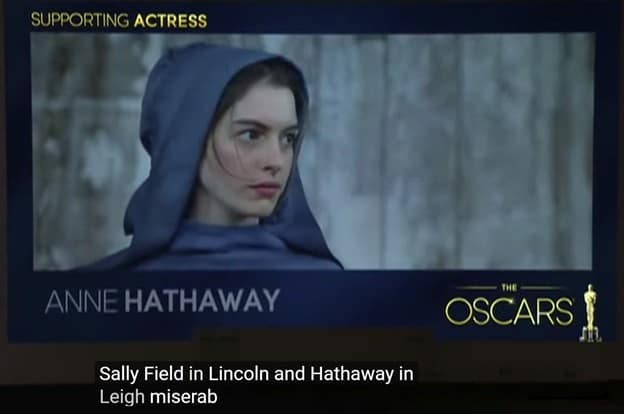
ASR also has difficulty capturing proper nouns, such as the name “Freddy Harteis” in the image below.

It also doesn’t do well with foreign phrases, words, and names.
Punctuation
Unassisted ASR captions routinely leave out punctuation, creating long, run-on sentences that make the captions confusing and often difficult to read. Periods, commas, and question marks are often missing or popping up where they do not belong, and rarely seen apostrophes, exclamation points, colons, semi-colons, or quotation marks all are par for the course with lone ASR. Human captioners know language as well as what punctuation to use and how and where to use it. They listen for natural breaks in dialogue and know the best ways to communicate that to the viewer.

Placement
Unassisted ASR captions do not change placement on their own, often covering on-screen graphics, scoreboards, and faces (a violation of FCC guidelines). VITAC captioners can change placement on the fly, and often do.
And we haven’t even mentioned unassisted ASR’s caption timing, where words sometimes appear onscreen for less than a second and then fly by at unreadable rates or, conversely, captions stay onscreen for five or more seconds, and then “catch up” in a hurry when pauses occur.
Or that some ASR engines do not identify speaker or subject changes, often running one speaker’s captions into another in the middle of a line.
Or the fact that unassisted ASR engines don’t self-correct as they don’t know their word choice was wrong. A human captioner who makes a mistake is trained to “dash off” the error and correct it, or rewrite the incorrect word.
Though it’s important that new technologies should be embraced, the rollout of these technologies, like ASR, without quality controls or testing or adhering to all FCC caption quality best practices is a disservice to caption viewers.
Captions provide an essential service to those in the deaf and hard-of-hearing community, and others, who, otherwise, would not be unable to enjoy, learn, or understand what’s playing out before them. Whether it be captions for a TV show, a classroom lecture, or a boardroom meeting – it’s all about accessibility, and expanding that access to everyone.
And that’s the job that our VITAC captioners embrace each day, bringing a human touch and art to their craft that no machine can on its own.